Sex, Text, and the Digit: Chopped/Screwed
11.2008
I. Language
"Otherwise we may (as most English children do) decide that everybody speaks English, and that it is silly to learn French." (Turing, 58)
I don't speak French. I've never taken a class, and I've never been in a situation where I've been able to pick up more than the most common of phrases from the language. With a background in John Searle's Chinese room argument, it can also be assumed that "the internet" as an entity in itself does not speak French. Given a computer with access to the web, and ample time however, I can (and have) come up with an intelligible and even passable French letter to a reader who does not speak English (and therefore cannot guess at my intentions through obvious mistakes like false cognates, etc.). Through this process, I continue to be able to converse with a Parisian acquaintance, though we share no common tongue, as well as a number of Spanish speaking friends (trip to Venezuela last spring) despite being far from conversationally adept in either of these languages.
While there are always new "revelations" on how the worldwide web can finally live up to its name thanks to the clever use of Google Translate and its various extensions, there is little talk of the larger implication this could have if teamed up with some already available and surprisingly old technologies. Text translation, like any manipulation of encoded material, is only effective so far as the material in need of manipulation can be effectively encoded. To simplify using a visual model which everyone understands: Suppose we have a scan (picture) of a page of a book or even a hand-written note. This takes up much more space (filesize) than the actual text would use if typed up. It also can't be manipulated- which could mean anything from changing font size/style, to being searched for key words, and (relevant here) even translated. It is most inconveniently fixed. Enter text recognition software-used quite notably by the online project Gutenberg- which can take scanned documents and convert them to .doc(uments), enabling these texts to be recorded at a fraction of the filesize and most importantly allowing for all sorts of the manipulations mentioned above. What was once fixed has become as fluid as binary code- ironically, here it is the analog which is machine like and rigid. This generalized process will henceforth be referred to as digitalization.
Picture to text software is nothing new, and can be found for free throughout the internet. The basic theory behind this process however, is one that actually holds what seems the most important step in the digital-analog convergence that is steadily increasing its rate and scope of influence on our society and very psyches. Returning to our original concern- further implications of steadily improving translation software- digitalization holds something almost as amazing for its potential influence as it is for its ability to remain un-talked-about right at the time when it has become most promising.
1960: "The basic dissimilarity between human languages and computer languages may be the most serious obstacle to true symbiosis. It is reassuring, however, to note what great strides have already been made...." (Licklider, 79)

Using only
free software and a steady internet connection, in half an hour I set up something which while on the surface appears as merely a clever exercise in futility, actually holds more social implications than most people seem to be aware of. The process is as follows: When I spoke into my computer's microphone input using a makeshift "mic", made out of the cheapest possible dollar-store headphones, into the freeware program "Wav To Text", what I said (carefully pronounced, see
digression 1) would appear in real time as on-screen text. This was then copied and pasted into Google Translate, which would convert the English message into Spanish. This Spanish message was then copied and pasted into a simple online text-to-speech converter, and turned into sound- the results of which actually can be seen at this link: http://tts.imtranslator.net/2cwi
The process can be summarized as follows: English speech----> English text---(Translation)----> Spanish text ----> Spanish speech (albeit robotized). Observing it in action- automated by a (free) windows macro program- is actually not very impressive. It takes about 40 seconds and sometimes doesn't work. Initial results
are impressive however, because my test phrase, "What are you doing here in New York?" was successfully converted into a HAL-like
voiced version of "¿Qué estás haciendo, aquí en Nueva York?" (the equivalent Spanish phrase)
without any human guidance. What is more impressive is the fact that this was done in perhaps the most "ghetto" way imaginable- all software was free, all websites are public, and the hardware was some of the cheapest and most readily available possible. This could be repeated by almost anyone, so long as they had access to a working computer and the internet. Imagine what could be accomplished if the amount of research and effort that was put into Google Translate itself was utilized on such a project (see
digression 2).

Fortunately, it seems that effort already
is being exerted in these sister areas. One of the most popular smart phone applications of the week is Google's "search by voice" on the iphone. This uses the exact same speech to text
(STT) technology that "Wav to Text" in my model employs, only the Google version is backed up by statistical data mining feedback as well as all the magic that makes their other services both more efficient, and
self improving. Simple STT systems are nothing new- in fact Microsoft office has included its own version since 2002, and everyone is far too familiar with the type that customer service centers employ to filter calls. These are fixed however, and do not improve, save through periodic updates. They would be the equivalent of the online Encyclopædia Britannica model of business. The type used by Google however, can improve itself through user input: the Wikipedia model
(WM) of voice-recognition.
To explain the process of this data-mining and recirculation would be the work of many volumes, however for the purpose of this venture, a simpler explanation will suffice. The Wikipedia model of user input as contribution as applied to Google Translate (GT): Users type text to be translated, which is sent through the GT database and returned in a different language. Users can see the translation, and provide their own better version for either the entire phrase or a single word. Their inquiries are also recorded and notes are made for words that were not yet in the system as having translations. This data is all recorded, filtered, and put into use. In this way, the system learns, although "Processes that are learnt do not produce a hundred percent certainty of result; if they did they could not be unlearnt" (Turing, 63). After all, a model like this, wherein interpersonal communication is involved, there is always bound to be some sort of trickery by witty users. This is practically a worn out subject in the debate on Wikipedia, as its administrators are often forced to put certain controversial subjects' pages on lockdown when people are fighting over informational distribution and vandalizing entire pages. GT continues to fight this problem (Spanish translation for Jesus = el gran mentiroso. Probably fixed already). Meta-messages at their finest.
"It's more about hyper-reality than about some sort of virtual reality."
- Bitter Nigger Inc. (Muhammad, 93)
Let us step back into my model for a moment. To simplify it even further and calling things by their rightful name, it can be shown as this: Analog (human voice)-----> Digital (text) ----(manipulation happens)-----> Analog (sound). This is the full circle digitalization of language. Similar such processes are everywhere. My fingers are pressing keys which are being turned into digits, which are being displayed as light which can be picked up by my eyes. A phone conversation is spoken, broken down into sampled (digitally approximated, quantized) waveforms, sent through a network, and converted into sound. Etc. Etc. Etc. Analog to digital to analog, encoding manipulating and decoding, throughout wireless modernity.
Of anything we could analyze, language, art, and love seem to be the most characteristically human, organic and analog. To understand the effect that this increasingly large digital grasp has had on their manifestations would be quite telling, as it is these areas of greatest contrast where bioconvergence (BC), or the combination of the analog with the digital has its most drastic and profound effects.
II. Art
"[Cybernetics] takes a dynamic view of life not unlike that of the artist." (Ascott, 129)
On Youtube there's a music video by the most popular rap lyricist of the day, Lil Wayne, entitled "Don't shoot me down." Interestingly, someone took the time to use one of the newest features of this video hosting site, which allows for closed captions (subtitles). What is even more interesting, is the newest integration between these captions and GT, which automatically switches them into one of 34 languages (currently, also see digression 2). The somewhat universal language of music just came one step closer to overcoming the timeless problem of lyrics, as people can listen to musical inflections and delivery while reading the singers' lingual content in real time- something almost impossible before this integration.
One particular lyric in this song, "because repetition is the father of learning..." is quite peculiar coming from an artist who self-admittedly refuses to write his lyrics. This technique is often highly criticized, and is one which saw similar debate amongst the jazz community years ago. The jazz composer and bass player Charles Mingus in 1971:
"When I was a kid and Coleman Hawkins played a solo or Illinois Jacquet created "Flyin' Home," they (and all the musicians) memorized their solos and played them back for the audience, because the audience had heard them on records. Today, things are at the other extreme. Everything is supposed to be invented, the guys never repeat anything at all and probably couldn't. They don't even write down their own tunes, they just make them up as they sit on the bandstand." (Liner Notes)
It would be tempting to label Lil Wayne's verse as simple stream of consciousness- random and unrepeatable- however this does not hold up. Another lyric from this song, "I'm a beast, I'm a dog...." is featured in at least two of his other compositions, "A Milli" and "I'm a beast". It can be inferred that he is reviewing and memorizing his own material though without ever lifting a pencil. Instead, recordings serves as a type extended memory (see digression 3), and certain cue words or epithets allow for spontaneous recollection of intricate material. This is a return to the Homeric tradition, the blind poet, the griot. Proven rhymes and combinations of words are stored up, while older material is reviewed and more phrases are added. Ironically, this is actually a more organic way of recording spoken poetry, as encoding it into writing would be one more step removed from its origin (and destination) as thought. There's also the fact that his music is popular enough that people transcribe lyrics almost the second his songs are released, which would save him some work.... Perhaps more eloquently and in his own words, responding to inquiries as to whether or not he really doesn't write anything down, "Uh-uh. I'd be too high for that" (Interview, 2004).
This model then, is one of art as almost formulaic, or digital. There is an equation to it. With this in mind, Pop artists such as Andy Warhol's "factory" method of production has become particularly relevant within modern art/media discourse. The most popular song of 2007, by the rapper Mims: "This is why I'm hot/I don't gotta rap/I can sell a mill[ion] saying nothing on the track/I represent New York/I got it on my back..." Focusing on the line "I can sell a million saying nothing on the track," it is very easy to recall Warhol's famous "piss paintings," which (literally) rub in his audience's noses the fact that one could create something completely devoid of artistic "skill" as it is usually interpreted- painting, lyrics, etc.- and by merely stamping the right name on it, sell it for millions. Both he and Mims successfully fulfilled the check-list for what makes a piece of art sellable; they correctly applied the formula. The "art" behind these pieces then, is a meta-discourse (miscourse) on the problems/gullibility of society and the art within it.
Within these lyrics are the echoes of an artist who (forty years ago) would purposefully work in the most conspicuously "lazy" way possible- having assistants paint from silkscreens he only traced from photographs he didn't take. This is the role of the artist as producer, not executor. Roy Ascott summed it up beautifully in 1964: "...man's relationship to his environment has changed. As a result of cybernetic efficiency, he finds himself becoming more and more predominantly a Controller and less an Effecter" (130). Traces of this can be seen from antiquity, where masters would complete the most difficult and impressive parts of a composition, and leave the tapestry work or unimportant minor figure work to their apprentices, thus freeing their own time for more conceptual work and also serving to educate these young assistants. Returning to this "#1 Billboard Single" from 2007, the freestyle remix by rapper Lil' Wayne contains something directly in keeping with this collage or remediation aesthetic: "Hip hop is mine now, Mine what you gone do?/I can jump on any nigga song and make a part two," which is exactly what he is doing as this is a remix of a pre-existing song, which today has more plays on youtube than the original itself. Therefore the only "work" he did, was to loop an already popular song, and freestyle new lyrics over it. This is the sketch artist, selling whatever he can come up with in ten minutes and sign at the bottom. In his own words, "...I don't write shit cuz I aint got time" (A Milli, 2008).  Here we see the artist who in legally free mixtapes, while simultaneously explaining to his audience just how little time he actually spends on the lyrics that they love, doesn't even bother to charge for his art, under the assumption that people will just steal it anyways- the ultimate form of flattery, and one which he actively supports and participates in due to his previously stated affinity toward stolen samples. While many other musicians are complaining about the "death of CDs" and other problems, Lil Wayne understands the contemporary channels of communication and how to manipulate them to his advantage. He manages to make money off of people stealing his music, which is poetic in and of itself. This very lyric is taken from a song who's musical content is solely made up of a less than second clip of another rapper saying "a milli-" looped over and over again. He also periodically releases mixtapes called "dedications", which are comprised of a single succesful formula: Lil Wayne rapping over the beats to the most popular songs of the past few years. Everything is stolen, disposable, transient, and last but certainly not least, big business (Hamilton, 1956). Nothing is fixed, and therefore nothing is final- "He who's laughing at the moment, laughs loudest." (see Digression 4)
Here we see the artist who in legally free mixtapes, while simultaneously explaining to his audience just how little time he actually spends on the lyrics that they love, doesn't even bother to charge for his art, under the assumption that people will just steal it anyways- the ultimate form of flattery, and one which he actively supports and participates in due to his previously stated affinity toward stolen samples. While many other musicians are complaining about the "death of CDs" and other problems, Lil Wayne understands the contemporary channels of communication and how to manipulate them to his advantage. He manages to make money off of people stealing his music, which is poetic in and of itself. This very lyric is taken from a song who's musical content is solely made up of a less than second clip of another rapper saying "a milli-" looped over and over again. He also periodically releases mixtapes called "dedications", which are comprised of a single succesful formula: Lil Wayne rapping over the beats to the most popular songs of the past few years. Everything is stolen, disposable, transient, and last but certainly not least, big business (Hamilton, 1956). Nothing is fixed, and therefore nothing is final- "He who's laughing at the moment, laughs loudest." (see Digression 4)
III. Love
"You and Josh are no longer friends."
Forget Match.com. Already on Facebook, arguably the most popular social networking site (SNS), there is an option called "suggest a friend," which uses statistic-based formulas to try and figure out who you know or should know in real life, and should therefore befriend on Facebook. What is this model based off of? Mostly just numbers of common friends and basic information such as what university in what city you each attend.
The potential this holds for the augmentation of love and (encodable definition: love - sex =) friendship continues to build as digitalization progresses. Using something familiar: The Netflix model
(NM) of movie recommendation and
predictive enjoyment is an amazing creature. First, you watch movies, then you give them a rating, which is logged into your personal profile. As this database begins to form, Netflix starts to get an idea of what type of movies you like, based off of your ratings and what "viewers like you" enjoy. This allows the service to suggest selections, and even predict what rating you will give a prospective movie
before the fact. It's all statistics that improve as the scope of your ratings increases. Therefore it is beneficial for both the service (like the WModel) as well as the individual for him/her to spend time honestly giving his/her opinions about movies. Users grow, service improves, and the system works. Often, out of stubbornness and distrust, I will select something that Netflix thinks is a bad idea, and more often than not it is this abstract formula that laughs last (as I give a low rating, as was predicted).
Lets imagine the NM were to be integrated into the "suggest a friend" as well as the newest Facebook installment "suggest a date". What type of ratings would be used? ratings of what? This presents a small problem, but one that is becoming increasingly insignificant as new web browsers and services (Chrome, del.icio.us, Evernote) collect meta-data as users surf the web. Many media based sites like youtube already implement their own rating systems ("viewers like you would probably enjoy the following videos...") but these new browsing services allow bookmarks with rating systems on almost any page on the internet. Intelligent filters could match similar articles and video/song locations (multiple locations) to understand that they correspond with each other or are similar. What I mean is that an individual profile could be developed as a user rated each piece of media, literature, art, music, etc., he/she encountered online. If integrated into something like Facebook, this profile could be used to algorithmically suggest friends. The formula would look something like this:
Friendship compatibility factor (
FCF) = geographic proximity +/- age difference +/- political stance +/- interests (profile) +/- hobbies (profile) +/- opinions of "friends like you" +/- race +/- language [maybe not so much anymore...........] +/- other
What about love? Your meta-data tracker (
macker) could also record what type of faces/bodies you find physically attractive in both sexes, like a version of the joke hotornot.com gone horribly serious. This might sound far fetched, but already "experiments suggest that a computer can use geometry to predict whether or not a face is attractive" (Highfield). Like everything here, the statistical NM makes everything more simplistic, as "voyeurs like you" will give ratings to the same pretty faces, and thus will establish a statistical base. With that in mind:
Date compatibility factor (
DCF) = already established friendship compatibility factor +/- predicted sexual attraction (shallowness profile) +/- opinions of "lovers like you"
We might laugh, claiming that love and friendship are too haphazard and unpredictable for any formula. I predict however, that like Netflix, resistance may be futile, contrived, and forced. It is nothing special that this type of service gives you a prediction of how well you will like something, but what
is scary, is that it is almost always correct.
However this is perhaps too simplistic, as the test is far from double-blind. The second I am told how well I will like something, there is a type of challenge that I am aware of while consuming whatever it is that is in question. It is a feedback loop that might positively or negatively effect my opinion of said item. Far from calming however, what does this mean when the subjects are interpersonal relationships instead of songs and DVDs? I'm not even close to prepared to answer that, but with Netflix I've already become weary enough of items poorly ranked in my profile that I avoid them like the plague.....that is unless someone who's opinion I greatly respect made the suggestion: DVD selectability factor = Netflix prediction +/- [(opinion) x (respect factor of the person who gave it)]. Sadly, this could also be placed into the equation. Greater statistical weight could be placed on the opinions of "viewers you trust". If there is a formula to something, it can and will be cracked, digitalized, and placed into the larger equation- no matter how "organic" it once was.
What each of these models shows, is an extension of BC and the combination of analog with digital. Enjoyment would generally be considered something analog, yet by artificially quantifying it and the factors involved, we are able to (pre)determine an outcome. Analog enjoyment is given a digital number which is used to select something else which delivers analog enjoyment. How much more significant is this process as it is applied to more important aspects of life. Perhaps this will prove to benefit the greater good and efficiency of the race: "By 'augmenting human intellect' we mean increasing the capability of a man to approach a complex problem situation, to gain comprehension to suit his particular needs, and to derive solutions to problems...and the possibility of finding solutions to problems that before seemed insoluble (see
digression 5)" (Engelbart, 95). Or perhaps the next generation is doomed to a statistical madhouse where people constantly allocate different amounts of stars to their friends and loved ones like a Lear-ish figure raising and lowering inheritance percentage points at the drop of a hat. It would be a little depressing to be able to actually see popularity in graph form, although we already compete to see who can amass more friend requests. It is important to remember: "...there is a chance of turning to the machine to human advantage, but the machine itself has no particular favor for humanity" (Weiner, 72).
Digression 1:
A quote talking about a program which could recognize handwritten letters in order to turn them into text: "...the operator would quickly learn to write or print in a manner legible to the machine" (Licklider, 80). Similarly, the process of learning to efficiently utilize Google Translate, can be mastered. One slowly becomes accustomed to what will and will not translate correctly. We learn how to correctly feed data in order to obtain useful results.
Taken from http://www.muegge.cc/controlled-language.htm:
"The author of this website used a controlled language in order to write this text in the German language. In a second step, a machine translation system translated the German text into the English language. Finally, a human translator corrected the translation mistakes of the machine translation software. The correction process required considerably less time than a traditional human translation process

.
Controlled Language Rule 1:
Write sentences that are shorter than 25 words.
Write:
The author performs the following tasks:
-
Collect the necessary information.
-
Analyze and evaluate the information.
-
Write a structured draft.
Do not write:
Authors will approach any writing project by collecting the necessary information first, and after carefully analyzing and evaluating it, they will create a structured draft."
This process though, if it becomes common practice to read blogs and websites in other languages, will have an effect on the writing style of the people who make these websites. It will have an effect on the language itself, because people will write in a way that is most easily translatable- both literally and figuratively. Puns don't translate. Situational comedy and certain imagery might. Therefore language itself- one of our oldest and most organic (analog) practices- might actually be effected, controlled, and stabalized by the governance of digitalization.
Digression 2:
So we've proven that two people without a common tongue could hold a spoken conversation in almost real time (the process could probably be shaved down to a 2 second delay). To make this a little less impersonal however, it would be nice not to have to rely on an artificial/robotic voice.
Enter this technology:
"When Prodigy's next album drops, it could debut in nearly 1,500 different languages without the rapper having to so much as crack a translation dictionary.The lyrics to "H.N.I.C. Part 2" will be translated using proprietary speech-conversion software developed by Voxonic.........
Here's how the Voxonic translation process works. After translating the lyrics by hand, the text is rerecorded by a professional speaker in the selected language. Proprietary software is used to extract phonemes, or basic sounds, from Prodigy's original recording to create a voice model. The model is then applied to the spoken translation to produce the new lyrics in Prodigy's voice. A 10-minute sample is all we need to imprint his voice in Spanish, Italian or any language," said Deutsch..... " (Wortham)
See it in action. Keep in mind that he doesn't know a word of Spanish:
http://youtube.com/watch?v=rlqatr9Fsjc
So a more complex version of my makeshift translation center would utilize similar technology, taking the text version of what it wants to say and using the voice profile (Josh's voice) that my device has built up and stored through hours of previous use, in order to produce the translated speech (as opposed to the robot voice). The way this works is by analyzing the exact overtones that makes my voice unique, through Fourier analysis (again, it's all down to a formula). Therefore, the listener would actually hear, "Entonces, ¿qué estás haciendo aquí, en Nueva York?" in what sounds like my own voice- even thought I've never been able to speak Spanish! I speak in English, he hears Spanish- He responds in Spanish, and I hear English, ad absurdum. What social effects would this have if plugged into a video chat service like SKYPE? "Google Video" was just integrated into all Gmail accounts as of 12/2008, and besides GT, they've been working on speech recognition for some time:
"Today, the Google speech team (part of Google Research) is launching the Google Elections Video Search gadget, our modest contribution to the electoral process. With the help of our speech recognition technologies, videos from YouTube's Politicians channels are automatically transcribed from speech to text and indexed. Using the gadget you can search not only the titles and descriptions of the videos, but also their spoken content. Additionally, since speech recognition tells us exactly when words are spoken in the video, you can jump right to the most relevant parts of the videos you find. Here's a look:
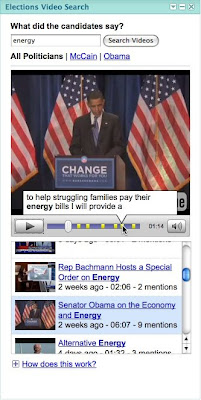
In addition to providing voters with election information, we also hope to find out more about how people use speech technology to search and consume videos, and to learn what works and what doesn't, to help us improve our products." (Bezman)
Also: "H. Samy Alim, a professor of anthropology at the University of California at Los Angeles who specializes in global hip-hop culture and sociolinguistics, also doubted the newly minted songs would retain the clever wordplay and innovative rhyme schemes inherent in popular music.
Besides, he laughed, "How do you translate 'fo shizzle' in a way that retains its creativity and humor for a global audience?" (Wortham)
While correct, I find this to be an oversimplification (see the end of digression 1). "Fo Shizzle" wouldn't be translated, because certain things are better left alone and learned. I don't need to have "Habibi" translated into "baby" in order to understand the lyrics of Amr Diab....
Digression 3:
"presumably man's spirit should be elevated if he can better review his shady past and analyze more completely and objectively his present problems." (Bush, 47)
Speaking of digitally extended memory:
"SenseCam is a wearable digital camera that is designed to take photographs passively, without user intervention, while it is being worn. Unlike a regular digital camera or a cameraphone, SenseCam does not have a viewfinder or a display that can be used to frame photos. Instead, it is fitted with a wide-angle (fish-eye) lens that maximizes its field-of-view. This ensures that nearly everything in the wearer’s view is captured by the camera, which is important because a regular wearable camera would likely produce many uninteresting images.
SenseCam also contains a number of different electronic sensors. These include light-intensity and light-color sensors, a passive infrared (body heat) detector, a temperature sensor, and a multiple-axis accelerometer. These sensors are monitored by the camera’s microprocessor, and certain changes in sensor readings can be used to automatically trigger a photograph to be taken.
For example, a significant change in light level, or the detection of body heat in front of the camera can cause the camera to take a picture. Alternatively, the user may elect to set SenseCam to operate on a timer, for example taking a picture every 30 seconds. We have also experimented with the incorporation of audio level detection, audio recording and GPS location sensing into SenseCam although these do not feature in the current hardware.

We currently fit 1Gb of flash memory, which can typically store over 30,000 images. Most users seem happy with the relatively low-resolution images, suggesting that the time-lapse, first-person-viewpoint sequences represent a useful media type that exists somewhere between still images and video. It also points to the fact that these are used as memory supports rather than rich media." (Microsoft, e.a.)
"Every person who does his thinking with symbolized concepts (whether in the form of the English language, pictographs, formal logic, or mathematics) should be able to benefit significantly." (Engelbart, 98)
Digression 4:
"Cut-and-mix is a genre known for its free form, ruptures, odd juxtapositions, and fragmentation.
I propose cut-and-mix as a legitimate methodology that locates revisionist interventions,
recovery processes, and futurist and retrofuturist agendas that have been built in relation to
postmodern and poststructuralist theoretical perspectives. Cut-and-mix methodology facilitates a
way to conceptualize visual media as process rather than object." (Muhammad, 91, e.a.)
Cut and mix (copy and paste) has also been adopted as a method of experience/memory through things such as Evernote (previously discussed). The "don't shoot me down" video by Lil Wayne is as good an example of remediation as any: Clips of the speaches Martin Luther King Jr. and John F. Kennedy were woven together both sonically and visually in order to create this music video. What is significant here is the lack of "new" content- rather this is an audio-visual collage, which although not entirely new, feeds directly into the subject of re-mediation as a second interpretive opportunity. These speeches were cut down to their most relevant moments for the artistic "discussion" at hand. This is visual (and other) media as process rather than object.
Digression 5:
"Every couple has its ups and downs, but most people try to keep their dirty laundry to themselves. But what about those times when you just can’t come to an agreement with your significant other?
Today sees the launch of SideTaker a site that asks couples to upload both sides of their arguments and let the crowd settle their debates. SideTaker members can vote on which side they agree with, or leave comments to ask for further details or voice their opinions.
The site is hilarious. Disputes range from cheating spouses to toilet flushing, oftentimes filled with more detail than anyone would want to know. (Kincaid, 2008)

Perhaps eventually we'll submit things like this and it will tell us what to do based on "f(x) = do this because (person) is in the wrong here." Once couples start to use it, it will build up database (using both the WM and NM), so in theory, you could submit a problem and based on what each user had said in similar situations in the past, it would calculate an estimate as to who is right (who everyone else would say is right if they actually wrote in) instantly. So you'd both type in your side of the story, agree on its accuracy, submit it, and get back something like: "77% side the girl, 14% side withwith the guy, 9% don't care, 68% say you both suck". And then he'll have to apologize or risk angering the "idol of the gadget" (Wiener, 71).
♠
---------
Haphazard References:
Bezman, Ari and Arnaud Sahuguet. "In their own words". July, 14 2008. http://googleblog.blogspot.com/2008/07/in-their-own-words-political-videos.html
Buch, Vannevar. "As We May Think". 1945. Taken From the "New Media Reader" edited by Wardrip and Montfort.
Carter, "Lil Wayne" Michael Jr. "A Milli". April 22, 2008. Universal.
Controlled Language Test Website. http://www.muegge.cc/
Engelbart, Douglas. "Augmenting Human Intellect". 1962. Taken From the "New Media Reader" edited by Wardrip and Montfort.
Hamilton, Richard. Definition of Pop Art from a letter to the Smithsons. January 16, 1957.
Highfield, Roger. "Computers can use geometry to predict pretty faces". March 5, 2008. http://www.gogeometry.com/world_news_map/computer_geometry_predict_pretty_face.html
Kincaid, Jason. "SideTaker: Crowdsourcing" September 5, 2008.
http://www.techcrunch.com/2008/09/05/sidetaker-crowdsourcing-your-private-disputes-with-hilarious-results/
Licklider, J.C.R. "Man-Computer Symbiosis". 1960. Taken From the "New Media Reader" edited by Wardrip and Montfort.
Microsoft. "Introducing the Sensecam". http://research.microsoft.com/en-us/um/cambridge/projects/sensecam/
Mims, Shawn. "This is why I'm Hot." Januay 23, 2007. Capitol Records.
Mingus, Charles. "Let My Children Hear Music". 1972. Columbia Records.
Muhammad, Erika Dalya. "Electrocultures". Namac: A Closer Look. 2005
Searle, John (January 1990), "Is the Brain's Mind a Computer Program?", Scientific American 262: 26-31 .
Turing, Alan. "Computing Machinery and Intelligence". 1950. Taken From the "New Media Reader" edited by Wardrip and Montfort.
Wiener, Norbert. "Men, Machines, and the World About". 1954. Taken From the "New Media Reader" edited by Wardrip and Montfort.
Wortham, Jenna. "Software Morphs Rapper Prodigy Into Global Cipher". January 18, 2008. http://www.wired.com/entertainment/music/news/2008/01/Prodigy
