
Description
This project applies spatialization and decorrelation techniques to create the illusion of multiple sources from a single input audio stream. It can be used, for example, to make a solo instrument sound like an ensemble, or a single voice sound like a room full of people. Depending on the parameters, it can also be used to create unique versions of more familiar effects- reverb, flanging, chorusing, pitch warping, etc.
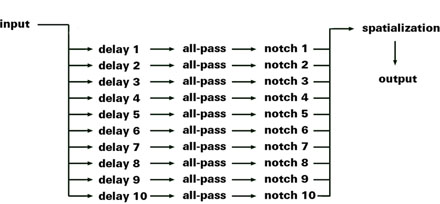
Traditional chorusing/upmixing techniques tend to suffer from phase cancellation and/or unnatural delay-time predictability, both of which subtract from the illusion and make it much more difficult to create a dense, realistic, sonic scene from relatively sparse input material. To combat the first problem I run each duplicated voice through a series of all-pass filters in order to scramble the phases and thus avoid cancellation along a fixed pattern. Similarly, in order to avoid predictable delay-time patterns, each voice is given its own unique delay waver value which determines a time range throughout which it moves ("wavers") back and forth over time. This creates an ever changing temporal and pitch relationship between the individual voices which enforces the illusion that they are independent entities. Additionally, since in reality every instrument or voice has its own unique frequency response, each duplicated voice is run through a unique band reject filter (a quick approximation where the unique timbre of a voice is determined by what it cuts out of the original signal). Finally, each voice is given a unique position in space, further heightening the sense of independence.
Examples
Input
Alternative content
Output
Alternative content
Input
Alternative content
Output
Alternative content
Input
Alternative content
Output
Alternative content
Technical Notes
Most of the difficulties of this technique come from unwanted artifacts of the upmixing process. Our ears are extremely adept at picking out patterns in sound, which means that every delay-line and filter shift must be triggered and changed at different times for each voice and must also interpolate this shift at a sporadic rate. Recalculating random shift values at extremely high frequencies seemed to solve this problem, but led to difficulties of its own- specifically unsustainable computational demands. Modifying how often new values were selected and staggering this process for each individual voice made the system both more realistic and less taxing on CPU, however there is still much work to be done as currently the program cannot handle more than ~12 voices.
Phase cancellation was another issue, and still needs much improvement. Although I was initially running each voice through 2-5 all-pass filters, a large breakthrough came when I started "cascading" them through ~30 filters, scrambling the phase much more drastically and therefore effectively. The inclusion of a unique band-reject filter for each voice also helped much more than I would have initially suspected.
This program is written in C++ using the Gamma library written by Lance Putnam. Spatialization is done in Sound Element Spatializer (SES) written by Ryan McGee.
Future Work
Besides increasing efficiency which would allow for many more voices, I'd like to make the system somewhat intelligent. Specifically, I think it should have an option to scale the delay waver based on the general range of the input source. While writing the program I noticed that lower instruments sounded much more "muddy" and dissonant with the same parameters, which leads me to believe that our ears are more forgiving in higher registers. The next version of the program could scale the delay waver accordingly. Additionally, it would be nice to have some sort of delay-waver-waver (meta-waver) that changed over time, either randomly or better yet in response to the music being played. Real players are much more/less together depending on the speed, feeling, syncopation, and complexity of a passage and it seems feasible that my program could simulate that phenomenon.
Conclusion
Although there's still much work to be done, in general I'm happy with the outcome. Currently, it's an effect, simple, and quick way to create large, spatialized audio scenes from very little source material. I think that it's one of the most realistic artificial "ensemble-izer" I've heard to date, and with further improvement it might actually be able to generate what a common listener couldn't distinguish from a real group of performers. Throughout the process I learned how formidable a challenge it is to perceptually decorrelate duplicated audio signals. It was also a lesson in psycho-acoustics that gives me new respect for just how sensitive our ears are to the subtle nuances of sound- a listener is often able to notice something odd even if he/she couldn't consciously put into words what that peculiarity is.